-
Choerodon平台版本: 0.16.0
-
遇到问题的执行步骤:
export ANSIBLE_HOST_KEY_CHECKING=False
#在kubeadm-ansible/目录下执行
ansible-playbook -i inventory/hosts -e @inventory/vars cluster.yml -K
-
文档地址:
http://choerodon.io/zh/docs/installation-configuration/steps/kubernetes/ -
环境信息(如:节点信息):
-
报错日志:
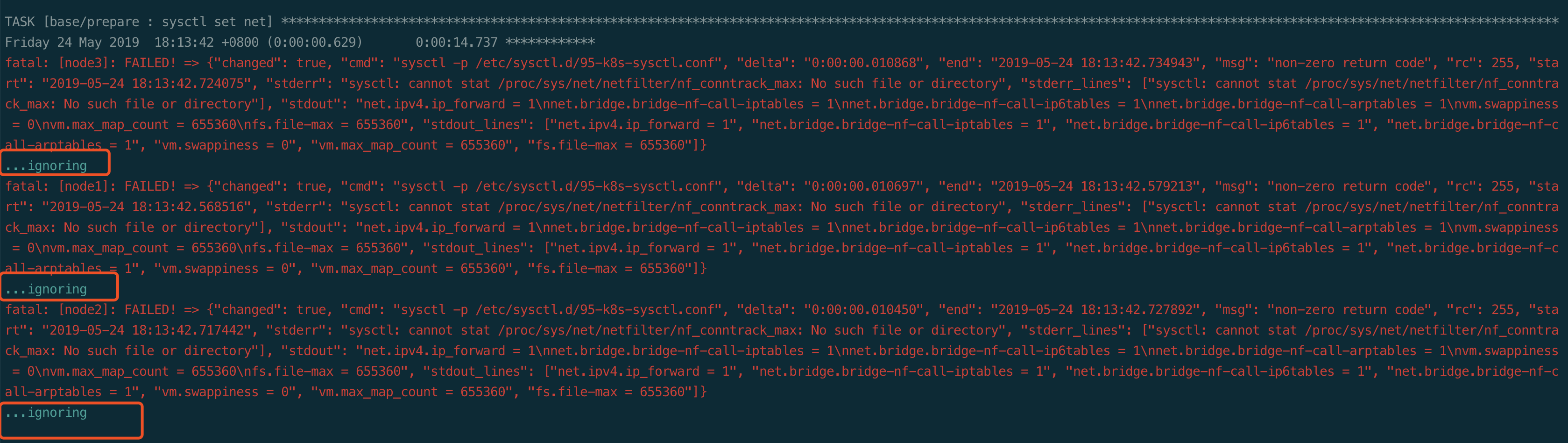
RUNNING HANDLER [etcd : wait for etcd up] ************************************************************************************************************************
Friday 24 May 2019 16:42:43 +0800 (0:00:00.276) 0:01:16.327 ************
FAILED - RETRYING: wait for etcd up (10 retries left).
FAILED - RETRYING: wait for etcd up (9 retries left).
FAILED - RETRYING: wait for etcd up (8 retries left).
FAILED - RETRYING: wait for etcd up (7 retries left).
FAILED - RETRYING: wait for etcd up (6 retries left).
FAILED - RETRYING: wait for etcd up (5 retries left).
FAILED - RETRYING: wait for etcd up (4 retries left).
FAILED - RETRYING: wait for etcd up (3 retries left).
FAILED - RETRYING: wait for etcd up (2 retries left).
FAILED - RETRYING: wait for etcd up (1 retries left).
fatal: [master]: FAILED! => {“attempts”: 10, “changed”: false, “content”: “”, “msg”: “Status code was -1 and not [200]: Request failed: <urlopen error [Errno 111] Connection refused>”, “redirected”: false, “status”: -1, “url”: “https://119.80.161.93:2379/health”}
如果不reset,再执行
ansible-playbook -i inventory/hosts -e @inventory/vars cluster.yml -K
会报另一个错
TASK [master : kubeadm | Initialize first master] ****************************************************************************************************************
Friday 24 May 2019 16:48:43 +0800 (0:00:01.237) 0:01:21.119 ************
卡在这里很久。大概卡半小时,之后报以下错。
fatal: [master]: FAILED! => {“changed”: true, “cmd”: [“kubeadm”, “init”, “–config=/etc/kubernetes/kubeadm-config.yaml”, “–ignore-preflight-errors=all”], “delta”: “0:30:21.078473”, “end”: “2019-05-24 17:19:05.039635”, “failed_when_result”: true, “msg”: “non-zero return code”, “rc”: 1, “start”: “2019-05-24 16:48:43.961162”, “stderr”: “\t[WARNING SystemVerification]: docker version is greater than the most recently validated version. Docker version: 18.03.1-ce. Max validated version: 17.03\nFlag --insecure-bind-address has been deprecated, This flag will be removed in a future version.\nFlag --insecure-port has been deprecated, This flag will be removed in a future version.\nFlag --admission-control has been deprecated, Use --enable-admission-plugins or --disable-admission-plugins instead. Will be removed in a future version.\n\t[WARNING ExternalEtcdVersion]: Get https://119.80.161.93:2379/version: dial tcp 119.80.161.93:2379: getsockopt: connection refused\ncouldn’t initialize a Kubernetes cluster”, “stderr_lines”: ["\t[WARNING SystemVerification]: docker version is greater than the most recently validated version. Docker version: 18.03.1-ce. Max validated version: 17.03", “Flag --insecure-bind-address has been deprecated, This flag will be removed in a future version.”, “Flag --insecure-port has been deprecated, This flag will be removed in a future version.”, “Flag --admission-control has been deprecated, Use --enable-admission-plugins or --disable-admission-plugins instead. Will be removed in a future version.”, “\t[WARNING ExternalEtcdVersion]: Get https://119.80.161.93:2379/version: dial tcp 119.80.161.93:2379: getsockopt: connection refused”, “couldn’t initialize a Kubernetes cluster”], “stdout”: “[init] Using Kubernetes version: v1.10.12\n[init] Using Authorization modes: [Node RBAC]\n[preflight] Running pre-flight checks.\n[certificates] Using the existing ca certificate and key.\n[certificates] Using the existing apiserver certificate and key.\n[certificates] Using the existing apiserver-kubelet-client certificate and key.\n[certificates] Using the existing sa key.\n[certificates] Using the existing front-proxy-ca certificate and key.\n[certificates] Using the existing front-proxy-client certificate and key.\n[certificates] Valid certificates and keys now exist in “/etc/kubernetes/pki”\n[kubeconfig] Wrote KubeConfig file to disk: “/etc/kubernetes/admin.conf”\n[kubeconfig] Wrote KubeConfig file to disk: “/etc/kubernetes/kubelet.conf”\n[kubeconfig] Wrote KubeConfig file to disk: “/etc/kubernetes/controller-manager.conf”\n[kubeconfig] Wrote KubeConfig file to disk: “/etc/kubernetes/scheduler.conf”\n[controlplane] Wrote Static Pod manifest for component kube-apiserver to “/etc/kubernetes/manifests/kube-apiserver.yaml”\n[controlplane] Wrote Static Pod manifest for component kube-controller-manager to “/etc/kubernetes/manifests/kube-controller-manager.yaml”\n[controlplane] Wrote Static Pod manifest for component kube-scheduler to “/etc/kubernetes/manifests/kube-scheduler.yaml”\n[init] Waiting for the kubelet to boot up the control plane as Static Pods from directory “/etc/kubernetes/manifests”.\n[init] This might take a minute or longer if the control plane images have to be pulled.\n\nUnfortunately, an error has occurred:\n\ttimed out waiting for the condition\n\nThis error is likely caused by:\n\t- The kubelet is not running\n\t- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)\n\t- Either there is no internet connection, or imagePullPolicy is set to “Never”,\n\t so the kubelet cannot pull or find the following control plane images:\n\t\t- registry.cn-hangzhou.aliyuncs.com/choerodon-tools/kube-apiserver-amd64:v1.10.12\n\t\t- registry.cn-hangzhou.aliyuncs.com/choerodon-tools/kube-controller-manager-amd64:v1.10.12\n\t\t- registry.cn-hangzhou.aliyuncs.com/choerodon-tools/kube-scheduler-amd64:v1.10.12\n\t\t- registry.cn-hangzhou.aliyuncs.com/choerodon-tools/etcd-amd64:3.1.12 (only if no external etcd endpoints are configured)\n\nIf you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:\n\t- ‘systemctl status kubelet’\n\t- ‘journalctl -xeu kubelet’”, “stdout_lines”: ["[init] Using Kubernetes version: v1.10.12", “[init] Using Authorization modes: [Node RBAC]”, “[preflight] Running pre-flight checks.”, “[certificates] Using the existing ca certificate and key.”, “[certificates] Using the existing apiserver certificate and key.”, “[certificates] Using the existing apiserver-kubelet-client certificate and key.”, “[certificates] Using the existing sa key.”, “[certificates] Using the existing front-proxy-ca certificate and key.”, “[certificates] Using the existing front-proxy-client certificate and key.”, “[certificates] Valid certificates and keys now exist in “/etc/kubernetes/pki””, “[kubeconfig] Wrote KubeConfig file to disk: “/etc/kubernetes/admin.conf””, “[kubeconfig] Wrote KubeConfig file to disk: “/etc/kubernetes/kubelet.conf””, “[kubeconfig] Wrote KubeConfig file to disk: “/etc/kubernetes/controller-manager.conf””, “[kubeconfig] Wrote KubeConfig file to disk: “/etc/kubernetes/scheduler.conf””, “[controlplane] Wrote Static Pod manifest for component kube-apiserver to “/etc/kubernetes/manifests/kube-apiserver.yaml””, “[controlplane] Wrote Static Pod manifest for component kube-controller-manager to “/etc/kubernetes/manifests/kube-controller-manager.yaml””, “[controlplane] Wrote Static Pod manifest for component kube-scheduler to “/etc/kubernetes/manifests/kube-scheduler.yaml””, “[init] Waiting for the kubelet to boot up the control plane as Static Pods from directory “/etc/kubernetes/manifests”.”, “[init] This might take a minute or longer if the control plane images have to be pulled.”, “”, “Unfortunately, an error has occurred:”, “\ttimed out waiting for the condition”, “”, “This error is likely caused by:”, “\t- The kubelet is not running”, “\t- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)”, “\t- Either there is no internet connection, or imagePullPolicy is set to “Never”,”, “\t so the kubelet cannot pull or find the following control plane images:”, “\t\t- registry.cn-hangzhou.aliyuncs.com/choerodon-tools/kube-apiserver-amd64:v1.10.12”, “\t\t- registry.cn-hangzhou.aliyuncs.com/choerodon-tools/kube-controller-manager-amd64:v1.10.12”, “\t\t- registry.cn-hangzhou.aliyuncs.com/choerodon-tools/kube-scheduler-amd64:v1.10.12”, “\t\t- registry.cn-hangzhou.aliyuncs.com/choerodon-tools/etcd-amd64:3.1.12 (only if no external etcd endpoints are configured)”, “”, “If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:”, “\t- ‘systemctl status kubelet’”, “\t- ‘journalctl -xeu kubelet’”]}
这次再 使用命令:ansible-playbook -i inventory/hosts -e @inventory/vars cluster.yml
不进行 reset.yml
会有新的错误:
TASK [master : kubeadm | delete old kube-dns service] ************************************************************************************************************
Friday 24 May 2019 17:23:13 +0800 (0:00:00.786) 0:00:48.212 ************
fatal: [master]: FAILED! => {“changed”: true, “cmd”: [“kubectl”, “delete”, “svc”, “kube-dns”, “-n”, “kube-system”], “delta”: “0:00:00.087298”, “end”: “2019-05-24 17:23:13.832321”, “msg”: “non-zero return code”, “rc”: 1, “start”: “2019-05-24 17:23:13.745023”, “stderr”: “error: the server doesn’t have a resource type “svc””, “stderr_lines”: [“error: the server doesn’t have a resource type “svc””], “stdout”: “”, “stdout_lines”: []}
…ignoring
TASK [master : kubeadm | create kube-dns service] ****************************************************************************************************************
Friday 24 May 2019 17:23:13 +0800 (0:00:00.349) 0:00:48.561 ************
fatal: [master]: FAILED! => {“changed”: true, “cmd”: [“kubectl”, “apply”, “-f”, “/etc/kubernetes/kube-dns-service.yml”], “delta”: “0:00:00.070228”, “end”: “2019-05-24 17:23:14.171394”, “msg”: “non-zero return code”, “rc”: 1, “start”: “2019-05-24 17:23:14.101166”, “stderr”: “The connection to the server localhost:8080 was refused - did you specify the right host or port?”, “stderr_lines”: [“The connection to the server localhost:8080 was refused - did you specify the right host or port?”], “stdout”: “”, “stdout_lines”: []}
…ignoring
TASK [master : Update kube-proxy command args] *******************************************************************************************************************
Friday 24 May 2019 17:23:14 +0800 (0:00:00.343) 0:00:48.904 ************
fatal: [master]: FAILED! => {“changed”: true, “cmd”: “kubectl -n kube-system get ds -l ‘k8s-app=kube-proxy’ -o json | jq '.items[0].spec.template.spec.containers[0].command += [”–masquerade-all"]’ | kubectl apply -f - && kubectl delete pods -n kube-system -l ‘k8s-app=kube-proxy’", “delta”: “0:00:00.079949”, “end”: “2019-05-24 17:23:14.516168”, “msg”: “non-zero return code”, “rc”: 1, “start”: “2019-05-24 17:23:14.436219”, “stderr”: “The connection to the server localhost:8080 was refused - did you specify the right host or port?\nerror: the server doesn’t have a resource type “ds””, “stderr_lines”: [“The connection to the server localhost:8080 was refused - did you specify the right host or port?”, “error: the server doesn’t have a resource type “ds””], “stdout”: “”, “stdout_lines”: []}
-
原因分析:
提出您分析问题的过程,以便我们能更准确的找到问题所在
-
疑问:
提出您对于遇到和解决该问题时的疑问