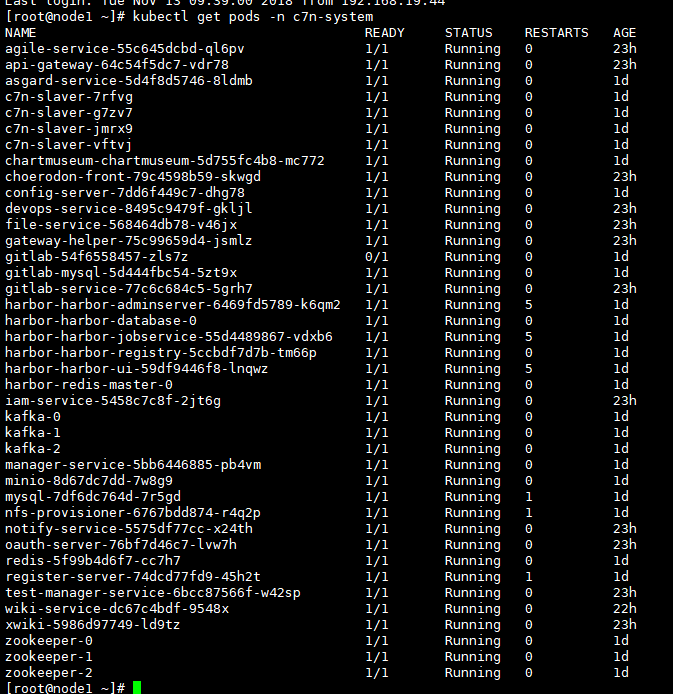
我用的是一键安装的方式,安装完成后访问一切正常,第二天就出现gitlab无法访问,C7N无法打开的情况,我看了几个重启过的POD的日志,麻烦您帮助看看
[root@node1 ~]# kubectl logs harbor-harbor-adminserver-6469fd5789-k6qm2 -n c7n-system
2018-11-12T07:41:52Z [INFO] initializing system configurations…
2018-11-12T07:41:53Z [INFO] Upgrading schema for pgsql …
2018-11-12T07:41:55Z [INFO] Registering database: type-PostgreSQL host-harbor-harbor-database port-5432 databse-registry sslmode-“disable”
2018-11-12T07:41:55Z [INFO] Register database completed
2018-11-12T07:41:55Z [INFO] the path of json configuration storage: /etc/adminserver/config/config.json
2018-11-12T07:41:55Z [INFO] the path of key used by key provider: /etc/adminserver/key
2018-11-12T07:41:56Z [INFO] system initialization completed
10.233.66.0 - - [12/Nov/2018:07:42:05 +0000] “GET /api/configurations HTTP/1.1” 200 1717
10.233.66.0 - - [12/Nov/2018:07:42:06 +0000] “GET /api/configurations HTTP/1.1” 200 1717
[root@node1 ~]# kubectl logs harbor-harbor-jobservice-55d4489867-vdxb6 -n c7n-system
2018-11-12T07:41:14Z [ERROR] [service_logger.go:63]: Job context initialization error: Get http://harbor-harbor-adminserver/api/configurations: dial tcp 10.233.18.151:80: i/o timeout
2018-11-12T07:41:14Z [INFO] Retry in 9 seconds
2018-11-12T07:41:53Z [ERROR] [service_logger.go:63]: Job context initialization error: Get http://harbor-harbor-adminserver/api/configurations: dial tcp 10.233.18.151:80: i/o timeout
2018-11-12T07:41:53Z [INFO] Retry in 13 seconds
2018-11-12T07:42:06Z [INFO] Registering database: type-PostgreSQL host-harbor-harbor-database port-5432 databse-registry sslmode-“disable”
2018-11-12T07:42:06Z [INFO] Register database completed
2018-11-12T07:42:06Z [INFO] Server is started at :8080 with http
2018-11-12T07:42:06Z [INFO] Logger sweeper is started
2018-11-12T07:42:06Z [INFO] OP commands sweeper is started
2018-11-12T07:42:06Z [INFO] Redis job stats manager is started
2018-11-12T07:42:06Z [INFO] Start to clear the job outdated log files
2018-11-12T07:42:06Z [INFO] 0 job outdated log files cleared
2018-11-12T07:42:06Z [INFO] Message server is started
2018-11-12T07:42:06Z [INFO] Subscribe redis channel {harbor_job_service_namespace}:period:policies:notifications
2018-11-12T07:42:06Z [INFO] Load 0 periodic job policies
2018-11-12T07:42:06Z [INFO] Periodic enqueuer is started
2018-11-12T07:42:06Z [INFO] Redis scheduler is started
2018-11-12T07:42:06Z [INFO] Redis worker pool is started
2018-11-12T13:12:16Z [INFO] Message server is stopped
2018-11-12T13:12:16Z [ERROR] [service_logger.go:63]: Message server exits with error: error occurred when receiving from pub/sub channel of message server: read tcp 10.233.66.8:58416->10.233.13.89:6379: use of closed network connection
2018-11-12T13:12:23Z [INFO] Restart message server (1 times)
ERROR: worker.fetch - read tcp 10.233.66.8:58412->10.233.13.89:6379: i/o timeout
ERROR: worker.fetch - read tcp 10.233.66.8:58418->10.233.13.89:6379: i/o timeout
ERROR: requeuer.process - read tcp 10.233.66.8:58414->10.233.13.89:6379: i/o timeout
ERROR: requeuer.process - read tcp 10.233.66.8:58420->10.233.13.89:6379: i/o timeout
2018-11-12T13:12:50Z [INFO] Message server is started
2018-11-12T13:12:50Z [INFO] Subscribe redis channel {harbor_job_service_namespace}:period:policies:notifications
[root@node1 ~]# kubectl logs harbor-harbor-ui-59df9446f8-lnqwz -n c7n-system
2018-11-12T07:42:06Z [DEBUG] [init.go:37]: topic StartReplication is subscribed
2018-11-12T07:42:06Z [DEBUG] [init.go:37]: topic OnPush is subscribed
2018-11-12T07:42:06Z [DEBUG] [init.go:37]: topic OnDeletion is subscribed
2018-11-12T07:42:06Z [DEBUG] [authenticator.go:126]: Registered authencation helper for auth mode: db_auth
2018-11-12T07:42:06Z [DEBUG] [authenticator.go:126]: Registered authencation helper for auth mode: ldap_auth
2018-11-12T07:42:06Z [DEBUG] [authenticator.go:126]: Registered authencation helper for auth mode: uaa_auth
2018-11-12T07:42:06Z [INFO] Config path: /etc/ui/app.conf
2018-11-12T07:42:06Z [INFO] initializing configurations…
2018-11-12T07:42:06Z [INFO] key path: /etc/ui/key
2018-11-12T07:42:06Z [INFO] initializing client for adminserver http://harbor-harbor-adminserver …
2018-11-12T07:42:06Z [INFO] initializing the project manager based on local database…
2018-11-12T07:42:06Z [INFO] configurations initialization completed
2018-11-12T07:42:06Z [INFO] Registering database: type-PostgreSQL host-harbor-harbor-database port-5432 databse-registry sslmode-“disable”
2018-11-12T07:42:06Z [INFO] Register database completed
2018-11-12T07:42:06Z [INFO] User id: 1 updated its encypted password successfully.
2018-11-12T07:42:06Z [INFO] Policy scheduler start at 2018-11-12T07:42:06Z
2018-11-12T07:42:06Z [ERROR] [main.go:162]: Failed to parse SYNC_REGISTRY: strconv.ParseBool: parsing “”: invalid syntax
2018-11-12T07:42:06Z [INFO] Because SYNC_REGISTRY set false , no need to sync registry
2018-11-12T07:42:06Z [INFO] Init proxy
2018/11/12 07:42:06 [I] [asm_amd64.s:2337] http server Running on http://:8080
root@node1 ~]# kubectl logs mysql-7df6dc764d-7r5gd -n c7n-system
2018-11-13T01:32:23.096091Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details).
2018-11-13T01:32:23.105751Z 0 [Note] mysqld (mysqld 5.7.22) starting as process 1 …
2018-11-13T01:32:23.124153Z 0 [Note] InnoDB: PUNCH HOLE support available
2018-11-13T01:32:23.124185Z 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2018-11-13T01:32:23.124189Z 0 [Note] InnoDB: Uses event mutexes
2018-11-13T01:32:23.124193Z 0 [Note] InnoDB: GCC builtin __atomic_thread_fence() is used for memory barrier
2018-11-13T01:32:23.124196Z 0 [Note] InnoDB: Compressed tables use zlib 1.2.3
2018-11-13T01:32:23.124199Z 0 [Note] InnoDB: Using Linux native AIO
2018-11-13T01:32:23.124783Z 0 [Note] InnoDB: Number of pools: 1
2018-11-13T01:32:23.124934Z 0 [Note] InnoDB: Using CPU crc32 instructions
2018-11-13T01:32:23.127243Z 0 [Note] InnoDB: Initializing buffer pool, total size = 128M, instances = 1, chunk size = 128M
2018-11-13T01:32:23.138957Z 0 [Note] InnoDB: Completed initialization of buffer pool
2018-11-13T01:32:23.142222Z 0 [Note] InnoDB: If the mysqld execution user is authorized, page cleaner thread priority can be changed. See the man page of setpriority().
2018-11-13T01:32:23.270212Z 0 [Note] InnoDB: Highest supported file format is Barracuda.
2018-11-13T01:32:23.286670Z 0 [Note] InnoDB: Log scan progressed past the checkpoint lsn 39140914
2018-11-13T01:32:23.286700Z 0 [Note] InnoDB: Doing recovery: scanned up to log sequence number 39140923
2018-11-13T01:32:23.286708Z 0 [Note] InnoDB: Database was not shutdown normally!
2018-11-13T01:32:23.286713Z 0 [Note] InnoDB: Starting crash recovery.
2018-11-13T01:32:25.238504Z 0 [Note] InnoDB: Removed temporary tablespace data file: “ibtmp1”
2018-11-13T01:32:25.238550Z 0 [Note] InnoDB: Creating shared tablespace for temporary tables
2018-11-13T01:32:25.241543Z 0 [Note] InnoDB: Setting file ‘./ibtmp1’ size to 12 MB. Physically writing the file full; Please wait …
2018-11-13T01:32:25.501702Z 0 [Note] InnoDB: File ‘./ibtmp1’ size is now 12 MB.
2018-11-13T01:32:25.509043Z 0 [Note] InnoDB: 96 redo rollback segment(s) found. 96 redo rollback segment(s) are active.
2018-11-13T01:32:25.509073Z 0 [Note] InnoDB: 32 non-redo rollback segment(s) are active.
2018-11-13T01:32:25.511051Z 0 [Note] InnoDB: Waiting for purge to start
2018-11-13T01:32:25.561276Z 0 [Note] InnoDB: 5.7.22 started; log sequence number 39140923
2018-11-13T01:32:25.562969Z 0 [Note] Plugin ‘FEDERATED’ is disabled.
2018-11-13T01:32:25.563147Z 0 [Note] InnoDB: Loading buffer pool(s) from /var/lib/mysql/ib_buffer_pool
2018-11-13T01:32:25.719502Z 0 [Note] InnoDB: Buffer pool(s) load completed at 181113 9:32:25
2018-11-13T01:32:25.731535Z 0 [Note] Found ca.pem, server-cert.pem and server-key.pem in data directory. Trying to enable SSL support using them.
2018-11-13T01:32:25.739050Z 0 [Warning] CA certificate ca.pem is self signed.
2018-11-13T01:32:25.742048Z 0 [Note] Server hostname (bind-address): ‘*’; port: 3306
2018-11-13T01:32:25.744214Z 0 [Note] IPv6 is not available.
2018-11-13T01:32:25.744247Z 0 [Note] - ‘0.0.0.0’ resolves to ‘0.0.0.0’;
2018-11-13T01:32:25.744288Z 0 [Note] Server socket created on IP: ‘0.0.0.0’.
2018-11-13T01:32:25.752126Z 0 [Warning] Insecure configuration for --pid-file: Location ‘/var/run/mysqld’ in the path is accessible to all OS users. Consider choosing a different directory.
2018-11-13T01:32:25.820137Z 0 [Warning] ‘user’ entry ‘root@localhost’ ignored in --skip-name-resolve mode.
2018-11-13T01:32:25.820214Z 0 [Warning] ‘user’ entry ‘mysql.session@localhost’ ignored in --skip-name-resolve mode.
2018-11-13T01:32:25.820231Z 0 [Warning] ‘user’ entry ‘mysql.sys@localhost’ ignored in --skip-name-resolve mode.
2018-11-13T01:32:25.821162Z 0 [Warning] ‘db’ entry ‘performance_schema mysql.session@localhost’ ignored in --skip-name-resolve mode.
2018-11-13T01:32:25.821186Z 0 [Warning] ‘db’ entry ‘sys mysql.sys@localhost’ ignored in --skip-name-resolve mode.
2018-11-13T01:32:25.821721Z 0 [Warning] ‘proxies_priv’ entry ‘@ root@localhost’ ignored in --skip-name-resolve mode.
2018-11-13T01:32:25.896832Z 0 [Warning] ‘tables_priv’ entry ‘user mysql.session@localhost’ ignored in --skip-name-resolve mode.
2018-11-13T01:32:25.896876Z 0 [Warning] ‘tables_priv’ entry ‘sys_config mysql.sys@localhost’ ignored in --skip-name-resolve mode.
2018-11-13T01:32:26.305038Z 0 [Note] Event Scheduler: Loaded 0 events
2018-11-13T01:32:26.305504Z 0 [Note] mysqld: ready for connections.
Version: ‘5.7.22’ socket: ‘/var/run/mysqld/mysqld.sock’ port: 3306 MySQL Community Server (GPL)
2018-11-13T02:31:08.467293Z 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 7784ms. The settings might not be optimal. (flushed=3 and evicted=0, during the time.)
2018-11-13T02:47:59.885743Z 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 5900ms. The settings might not be optimal. (flushed=3 and evicted=0, during the time.)
2018-11-13T03:04:18.262290Z 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 8714ms. The settings might not be optimal. (flushed=3 and evicted=0, during the time.)
2018-11-13T09:32:26.480109Z 4 [Note] Aborted connection 4 to db: ‘asgard_service’ user: ‘choerodon’ host: ‘10.233.64.0’ (Got timeout reading communication packets)
2018-11-13T09:51:16.150190Z 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 6394ms. The settings might not be optimal. (flushed=3 and evicted=0, during the time.)
2018-11-13T10:02:07.500194Z 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 4548ms. The settings might not be optimal. (flushed=0 and evicted=0, during the time.)
2018-11-13T10:04:34.802214Z 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 9627ms. The settings might not be optimal. (flushed=3 and evicted=0, during the time.)
2018-11-13T10:04:42.872862Z 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 7070ms. The settings might not be optimal. (flushed=0 and evicted=0, during the time.)
2018-11-13T09:32:26.480109Z 4 [Note] Aborted connection 4 to db: ‘asgard_service’ user: ‘choerodon’ host: ‘10.233.64.0’ (Got timeout reading communication packets)
2018-11-13T13:48:51.461836Z 7 [Note] Aborted connection 7 to db: ‘asgard_service’ user: ‘choerodon’ host: ‘10.233.64.0’ (Got timeout reading communication packets)
2018-11-14T07:59:53.047309Z 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 14053ms. The settings might not be optimal. (flushed=0 and evicted=0, during the time.)
2018-11-14T08:00:01.254120Z 8104 [Note] Aborted connection 8104 to db: ‘xwiki’ user: ‘choerodon’ host: ‘10.233.67.1’ (Got timeout reading communication packets)
2018-11-14T08:28:24.142173Z 16 [Note] Aborted connection 16 to db: ‘manager_service’ user: ‘choerodon’ host: ‘10.233.65.0’ (Got timeout reading communication packets)
2018-11-14T20:28:33.776146Z 3 [Note] Aborted connection 3 to db: ‘asgard_service’ user: ‘choerodon’ host: ‘10.233.64.0’ (Got timeout reading communication packets)
2018-11-14T21:00:54.498867Z 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 4919ms. The settings might not be optimal. (flushed=0 and evicted=0, during the time.)
2018-11-14T21:01:26.176594Z 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 6675ms. The settings might not be optimal. (flushed=3 and evicted=0, during the time.)
2018-11-14T21:41:52.995537Z 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 4092ms. The settings might not be optimal. (flushed=3 and evicted=0, during the time.)
2018-11-14T21:42:03.390162Z 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 6394ms. The settings might not be optimal. (flushed=3 and evicted=0, during the time.)
2018-11-14T21:49:11.933336Z 12193 [Note] Aborted connection 12193 to db: ‘manager_service’ user: ‘choerodon’ host: ‘10.233.65.0’ (Got timeout reading communication packets)
root@node1 ~]# kubectl logs nfs-provisioner-6767bdd874-r4q2p -n c7n-system
I1112 13:11:19.846455 1 main.go:63] Provisioner choerodon.io/nfs-provisioner specified
I1112 13:11:19.846544 1 main.go:87] Setting up NFS server!
I1112 13:11:20.025408 1 server.go:144] starting RLIMIT_NOFILE rlimit.Cur 65536, rlimit.Max 65536
I1112 13:11:20.025451 1 server.go:155] ending RLIMIT_NOFILE rlimit.Cur 1048576, rlimit.Max 1048576
I1112 13:11:20.026074 1 server.go:129] Running NFS server!
I1112 13:11:25.079928 1 leaderelection.go:185] attempting to acquire leader lease c7n-system/choerodon.io-nfs-provisioner…
I1112 13:11:42.495277 1 leaderelection.go:194] successfully acquired lease c7n-system/choerodon.io-nfs-provisioner
I1112 13:11:42.495388 1 controller.go:631] Starting provisioner controller choerodon.io/nfs-provisioner_nfs-provisioner-6767bdd874-r4q2p_7529a3ee-e67c-11e8-9e64-0a580ae94005!
I1112 13:11:42.495381 1 event.go:221] Event(v1.ObjectReference{Kind:“Endpoints”, Namespace:“c7n-system”, Name:“choerodon.io-nfs-provisioner”, UID:“53db89a8-e62d-11e8-b387-02cdc66c8a33”, APIVersion:“v1”, ResourceVersion:“81949”, FieldPath:""}): type: ‘Normal’ reason: ‘LeaderElection’ nfs-provisioner-6767bdd874-r4q2p_7529a3ee-e67c-11e8-9e64-0a580ae94005 became leader
I1112 13:11:42.595683 1 controller.go:680] Started provisioner controller choerodon.io/nfs-provisioner_nfs-provisioner-6767bdd874-r4q2p_7529a3ee-e67c-11e8-9e64-0a580ae94005!
E1112 16:12:16.789670 1 leaderelection.go:268] Failed to update lock: etcdserver: request timed out, possibly due to previous leader failure
E1113 03:40:13.275179 1 leaderelection.go:268] Failed to update lock: etcdserver: request timed out
E1113 06:15:57.463731 1 leaderelection.go:268] Failed to update lock: etcdserver: request timed out, possibly due to previous leader failure
E1113 11:21:44.356621 1 leaderelection.go:268] Failed to update lock: etcdserver: request timed out, possibly due to previous leader failure
E1114 02:43:41.292293 1 leaderelection.go:268] Failed to update lock: etcdserver: request timed out
E1114 02:53:28.952884 1 leaderelection.go:268] Failed to update lock: etcdserver: request timed out, possibly due to previous leader failure
E1114 03:00:56.624165 1 leaderelection.go:268] Failed to update lock: etcdserver: request timed out
E1114 03:40:06.685927 1 leaderelection.go:268] Failed to update lock: etcdserver: request timed out
E1114 04:46:36.640681 1 leaderelection.go:268] Failed to update lock: etcdserver: request timed out
E1114 08:42:20.748921 1 leaderelection.go:268] Failed to update lock: etcdserver: request timed out
E1114 11:22:13.879954 1 leaderelection.go:268] Failed to update lock: etcdserver: request timed out, possibly due to previous leader failure
E1114 19:50:45.632462 1 leaderelection.go:268] Failed to update lock: etcdserver: request timed out
E1114 23:00:52.873317 1 leaderelection.go:268] Failed to update lock: etcdserver: request timed out, possibly due to previous leader failure
[root@node1 ~]# kubectl logs register-server-74dcd77fd9-45h2t -n c7n-system
W1115 00:34:19.426514 1 client_config.go:529] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
I1115 00:34:19.428530 1 controller.go:60] Setting up event handlers
I1115 00:34:19.428594 1 apps.go:32] Register eureka app APIs
I1115 00:34:19.430600 1 server.go:45] Started server
I1115 00:34:19.432702 1 controller.go:93] Starting Pod controller
I1115 00:34:19.432720 1 controller.go:96] Waiting for informer caches to sync
I1115 00:34:19.440670 1 leaderelection.go:174] attempting to acquire leader lease…
I1115 00:34:19.532864 1 controller.go:106] Starting workers
I1115 00:34:19.532915 1 controller.go:115] Started workers
I1115 00:34:19.533154 1 repository.go:62] Delete instance by key c7n-system/register-server-74dcd77fd9-45h2t not exist
E1115 00:34:37.675265 1 event.go:260] Could not construct reference to: ‘&v1.Endpoints{TypeMeta:v1.TypeMeta{Kind:"", APIVersion:""}, ObjectMeta:v1.ObjectMeta{Name:“register-server”, GenerateName:"", Namespace:“c7n-system”, SelfLink:"/api/v1/namespaces/c7n-system/endpoints/register-server", UID:“7e8f5ee6-e64c-11e8-9598-02d0f28c71e8”, ResourceVersion:“526139”, Generation:0, CreationTimestamp:v1.Time{Time:time.Time{wall:0x0, ext:63677604485, loc:(*time.Location)(0x1baeb80)}}, DeletionTimestamp:(*v1.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string{“choerodon.io/release":"register-server”}, Annotations:map[string]string{“control-plane.alpha.kubernetes.io/leader":"{“holderIdentity”:“register-server-74dcd77fd9-45h2t1542213259440538957”,“leaseDurationSeconds”:15,“acquireTime”:“2018-11-14T16:34:37Z”,“renewTime”:“2018-11-14T16:34:37Z”,“leaderTransitions”:8}”}, OwnerReferences:[]v1.OwnerReference(nil), Initializers:(*v1.Initializers)(nil), Finalizers:[]string(nil), ClusterName:""}, Subsets:[]v1.EndpointSubset(nil)}’ due to: ‘no kind is registered for the type v1.Endpoints’. Will not report event: ‘Normal’ ‘LeaderElection’ ‘register-server-74dcd77fd9-45h2t1542213259440538957 became leader’
I1115 00:34:37.675613 1 leaderelection.go:184] successfully acquired lease c7n-system/register-server
E1115 03:22:25.299276 1 leaderelection.go:258] Failed to update lock: etcdserver: request timed out, possibly due to previous leader failure
E1115 03:50:45.446918 1 leaderelection.go:258] Failed to update lock: etcdserver: request timed out
E1115 07:00:52.263093 1 leaderelection.go:258] Failed to update lock: etcdserver: request timed out